정리 글 항목
Week 2에서 배우는 것
- Exploratory Data Analysis(EDA) 과정
- Validation Scheme
- Data Leakage (아래 추가 읽을 거리를 참고하시면 더 좋습니다.)
추가 읽을 거리 : 머신러닝 모델링의 흔한 실수들(17페이지 참고)
Exploratory Data Analysis
 |
| Data Science 프로세스(출처) |
EDA란 무엇인가?
- EDA란 : 데이터를 더 잘 이해하고, 직관(Intuition)을 얻으며, 가설을 생성하고, 통찰(Insight)을 도출하는 과정
- EDA 장점
- EDA 과정에서 데이터에 친숙해질 수 있음
- 문제 해결을 위해 필요한 특징(Feature)들을 찾아나갈 수 있음
- 모델링하기 이전에 EDA 과정을 거치는 것을 추천
- Visualization : EDA를 위해 데이터나 테스트한 결과를 시각화 필요
- Visualization → Idea : 시각화한 패턴에서부터 문제 해결에 필요한 질문 도출 가능
- Idea → Visualization : 문제 해결을 위해 설정한 가설(Hypothesis) 테스트 가능
데이터로부터 직관 얻기
- Domain 지식 얻기 : 해결해야될 문제를 이해하는데 도움이 됌
- 어떤 문제 해결을 목표로하는지, 어떤 데이터를 가지고 있는지, 주로 어떤 방법이 사용되는지 확인 필요
- 데이터가 직관적인지 확인 : Domain 지식에 부합하는지 판단 가능
- 주어진 데이터의 range가 적절한지, 오류의 가능성은 없는지 등을 확인
- 데이터 range 확인 : 나이 데이터에서 250임을 확인, 이 데이터가 사람 나이라면 수용하기 힘들지만 거북이 나이라면 수용 가능
- 오류 가능성 확인 : 웹에서 특정 이미지가 클릭된 기록이 있으나 물리적인 마우스의 클릭 횟수 기록이 0일 때, 사용자가 누르지도 않았는데 클릭 기록이 있으므로 오류 가능성
- 데이터가 어떻게 생성되었는지 확인 : 적절한 Validation Scheme을 세우기 위해서 이해 필요
익명화된(Anonymized) 데이터 탐색
 |
| 개인정보 비식별화 예시(출처) |
- 익명화된 데이터 : 원본 데이터에서의 정보를 식별할 수 없도록 가공한 데이터, 비식별화와 같은 의미로 사용됨
- 데이터 활용
- Feature Decode : 각 Feature들을 Decode하여 원래 의미를 유추해보기
- Feature Type 추측 : Type마다 필요한 전처리 과정을 추측
시각화
- 시각화 목적
- 개별 Feature 탐색 : Histogram, Plot, Statistics 활용
- Feature 관계 탐색 : Scatter Plots, Correlation Plots, Index vs Feature Statistics Plot 활용
- Index vs Feature Statistics Plot : plt.plot(x, '.'), plt.scatter(range(len(x)), x, c=y)
- 개별 Feature 탐색 위한 Tool
- matplotlib : hist, plot, scatter
- pandas : describe, mean, var, value_counts, is_null
- Feature 관계 탐색 위한 Tool
- matplotlib : scatter, scatter.matrix
- pandas : corr, mean (for clustering)
데이터 정제
- Constant 혹은 중복된 Feature들을 제거
- Constant Feature : 모든 행에서 같은 값을 가지는 데이터 혹은 Train 데이터에서만 같은 값을 가지는 데이터는 제거 필요
- 중복된 Feature : 두 Feature가 모든 행에서 같은 값을 가지는 데이터는 제거 필요(pandas에서 trainset.T.drop_duplicates()로 쉽게 제거 가능)
- 중복된 행을 제거
- 데이터셋이 적절히 셔플되었는지 확인 : 적절히 셔플되었다면 Train 데이터셋의 mean이 Test 데이터셋의 mean 값 근처에서 관측될 것
추가 읽을 거리
- Graph 시각화 : Graph Visualization with NetworkX
Validation
배울 것
- Validation과 Overfitting의 개념에 대한 이해
- 적합한 Validation을 위해 필요한 데이터셋 Split의 수 찾기
- Train, Test Split을 위해 자주 사용되는 방법 탐색
Validation과 Overfitting
 |
| Train, Validation, Test 데이터셋 분할(출처) |
 |
| 예측 결과로 보는 Underfitting과 Overfitting(출처) |
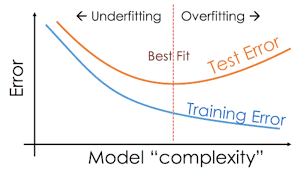 |
| Loss 값으로 보는 Underfitting과 Overfitting(출처) |
- 수집한 데이터셋을 Train, Validation, Test 데이터셋으로 분할
- Train : 학습에 사용되는 데이터
- Validation : 학습 과정 중 평가에 사용되는 데이터셋, 학습 데이터로도 사용 됨
- Test : 모델 평가에 사용되는 데이터셋. Competition에서는 Public, Private으로도 나뉘기도함
- Validation으로 살펴보는 모델 학습 상태
- Underfitting : 학습 데이터를 제대로 학습하지 못한 상태. 학습 데이터에 대해서도 모델 성능이 낮음
- Overfitting : 학습 데이터를 과하게 학습한 상태. 일반화 성능이 부족하여 학습 데이터 이외의 데이터에서는 제대로 동작하지 않음
Validation 전략
 |
| Holdout(출처) |
 |
| K-fold(출처) |
 |
| Leave-one-out(출처) |
- Validation 종류
- Holdout : Train, (Validation), Test 데이터셋으로 분리하는 방법. 데이터셋 크기가 작다면 오버피팅 될 가능성 높음
- K-fold : Train, Test 데이터셋을 나눈 후, Train 데이터셋 내에서 K 개의 Subset으로 분할. (K-1)개는 Train, 1개는 Validation으로 사용하며, 매 학습이 끝날 때마다 Validation으로 선택되는 Subset을 변경 후 다시 학습 진행
- Leave-one-out : 이름 그대로 1개의 데이터만 Validation용으로 분리하고 모두 학습에 활용. 모든 데이터가 1번씩 Validation에 사용될 수 있도록 N개의 데이터가 있을 때 N번의 반복
- 데이터 분할 전략
 |
| 개, 고양이 데이터셋(출처) |
- Validation 혹은 테스트 데이터를 예측할 수 있도록 Train 데이터셋 분할 필요
- 개, 고양이를 분류하는 모델을 학습시킨다고 가정
- 개 이미지로만 학습시키고 고양이 이미지로만 Validation 테스트 시도
- 고양이 이미지의 Feature를 배우지 못하였기에 성능이 낮은 결과 발생 가능
- 데이터 Feature, 타겟, 사용하는 모델 등에 따라 다른 전략 시도 필요
- Random : 각 데이터 row마다 random하게 분할
- Timewise : Week, Month 등으로 분할
- ID : User ID 등 고유한 번호로 분리(Clustering 문제로도 볼 수 있음)
- Combined : Timewise, ID를 함께 사용하는 등 여러 방법을 함께 사용하여 분할
- 추가 읽을 거리
Validation 중 발생할 수 있는 문제
- Validation 단계
- 일반화 할만큼 충분치 못한 데이터 수를 가지거나
- 데이터셋의 특징이 지나치게 다양하고 일관성이 없음
- Validation Score들 사이의 편차가 큼
- K-fold마다 평가한 성능들의 Average Score 사용하거나 1개 Split에 모델 튜닝하고 다른 Split으로 평가하는 등의 방법 사용 필요
- Submission 단계
- Leader Board Score가 Validation Score에 상관없이 일정하거나 상관 관계를 가지지 않음
- Public Leader Board에 너무 적은 데이터만 있거나, Train과 Test 데이터의 분포가 다르기 때문일 수 있음(위 개, 고양이 데이터 예시 참고)
- 지나치게 Overfitting 되거나 Train/Test 데이터가 적절하게 분할되었는지 확인 필요
- Leader Board Shuffle 발생
- Randomness, 데이터 수 부족, Public/Private 데이터셋의 다른 분포 때문에 발생 가능
Data Leakage
- 예측 모델의 목적 : 학습 데이터에 포함되지 않은 새로운 데이터를 높은 정확도로 예측할 수 있는 모델 개발
- Data Leakage : 우리(개발하는 사람)이나 모델이 모른다고 가정한 정보가 모델 학습에 사용되는 것
- Target Leakage : 예측 시 사용할 수 없는 데이터가 학습 데이터셋에 포함될 때

- 폐렴 걸린 여부(got_pneumonia)를 예측하는데, 항생제 맞은 여부(took_antibiotic_medicine) 입력은 적절치 않음
- 폐렴 걸린 이전에 폐렴을 예측하고자 하는데, 항생제 맞는 것은 폐렴 걸린 이후에나 맞는 것이기 때문
- Train-Test Contamination : 테스트로 사용되어야 될 데이터가 학습 데이터에 포함될 때
Leaks in times series
- 시간에 따라 데이터가 Split 되어야 함
- 실생활에서는 미래에 대한 정보가 없기 때문
- Competition에서는 train/public/private split이 시간에 따라 분할 되었는지 확인
How to Win a Data Science Competition: Learn from Top Kagglers-Week 2 강의 내용 정리
 Reviewed by parkjh
on
11월 03, 2021
Rating:
Reviewed by parkjh
on
11월 03, 2021
Rating:
Reviewed by parkjh
on
11월 03, 2021
Rating:






{kind=link}
{kind=link}
{kind=link}
댓글 없음: